Most AI detectors give you a verdict. AI or not AI. Red or green. A label that collapses whatever uncertainty the model had into a binary output that tells you almost nothing useful about your specific situation.
TextSight does something different. Instead of a verdict, it gives you a score from 0 to 100. And I want to explain exactly what that score represents, what the five bands mean in practice, and — most importantly — what actually moves it in either direction.
This is the post I wish existed when I first started using the tool.
First: What the Score Is NOT
Let's clear this up immediately, because it's the most common misconception.
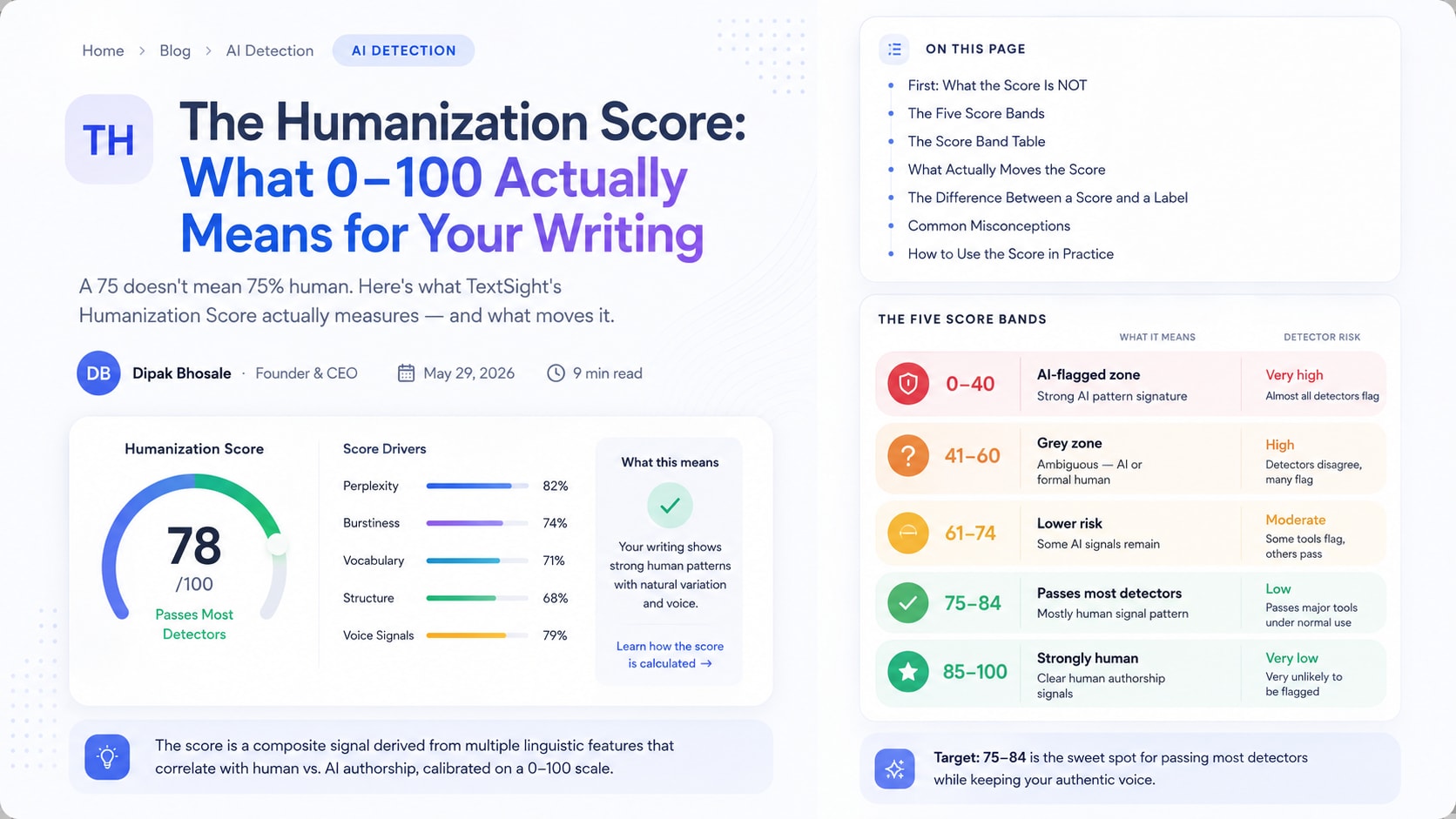
A Humanization Score of 75 does not mean "75% of this text is human." It's not a percentage of human-written words. It's not a confidence interval. It doesn't mean 75 out of 100 sentences passed some test.
The score is a composite signal derived from multiple linguistic features that correlate with human vs. AI authorship. Think of it as a probability-weighted assessment of how "human" the writing patterns are, expressed on a calibrated 0–100 scale. The scale is anchored so that known human writing clusters around 75–85, and known raw AI output clusters around 25–50.
That calibration is what makes the score useful. A 63 doesn't mean "mostly human." It means the text sits in a zone where detectors will likely scrutinize it, where some features read human and some don't, and where targeted revisions can move it significantly.
The Five Score Bands
Here's how TextSight defines the ranges, and what they actually mean in the real world.
0–40: Will Be Flagged
Text in this range has a strong AI-pattern signature. Raw GPT-4o output typically scores 22–38. Raw GPT-5 output (less detectable by design) typically scores 35–52, though it often dips into this band.
What you see at this score level: heavy over-representation of AI-associated phrases, low sentence length variance, predictable paragraph structure, sparse personal voice signals. The writing may be perfectly grammatical and coherent. It often is. That's not the issue. The issue is that every structural and lexical choice is statistically over-probable — it's what a model trained on the internet would write, rather than what a specific person chose to write.
Real-world equivalent: Submitted work that's essentially unedited AI output. Most school-level detectors flag this. Turnitin and GPTZero both typically return "likely AI" verdicts in this range.
41–60: Grey Zone
This is the most interesting band — and honestly the most dangerous one. It's interesting because text here is genuinely ambiguous. Some features read human, some read AI. The writing might be AI that's been edited, or it might be a human writer who uses formal prose patterns that overlap with AI style.
Detectors disagree most in this range. GPTZero might say 78% AI probability. ZeroGPT might say 45%. Neither is definitively right. What TextSight is telling you with a score of 55 is: this text is a coin flip for most binary detectors, and you should treat it as contested territory.
Real-world equivalent: An AI-assisted draft where maybe 30–40% of the original text was rewritten. Or a formal academic essay by a non-native English speaker. Or content from a professional who writes in a structured style that happens to resemble AI patterns.
61–74: Lower Risk
Text in this range passes some detectors and triggers others. GPTZero's paid tier might flag it as "likely AI assisted." TextSight's own calibration puts this zone as below the threshold where most automated flags would stick.
Here's my take on this range: a score of 68 isn't "safe." It's "low-risk but not clean." For casual use — a blog post, a LinkedIn update, a business report that nobody's going to scrutinize — it probably doesn't matter. For academic submissions, you'd want to push higher.
Real-world equivalent: AI-generated text with significant human editing (40%+ rewrite), or human writing with some structural habits that score poorly.
75–84: Passes Most Detectors
This is the target range for most users. Text here has enough human signal — sentence length variation, personal voice markers, specific examples, varied paragraph openers — that the major detectors don't flag it under normal conditions.
GPTZero and ZeroGPT typically return green in this range. Originality.ai, which is more aggressive, sometimes flags at 75–78. Turnitin's AI detection, generally considered the toughest standard, passes cleanly at 80+.
Real-world equivalent: Human writing, lightly AI-assisted and well-edited, or strong human writing with occasional formal patterns.
85–100: Reads Strongly Human
Clear human signal. Specific details, idiosyncratic phrasing, varying sentence structures, personal voice. This is where most native English speakers who write naturally land, without any AI assistance.
One thing worth noting: a score above 90 isn't meaningfully "more human" than a score of 85. The difference in real-world detector behavior between 87 and 94 is negligible. The practical goal is to get above 80, not to chase 100.
Real-world equivalent: Personal essays, journalism, casual blog writing, authentic human communication.
The Score Band Table
| Score Range | Band Name | What It Means | Detector Risk |
|---|---|---|---|
| 0–40 | AI-flagged zone | Strong AI pattern signature | Very high — almost all detectors flag |
| 41–60 | Grey zone | Ambiguous — AI or formal human | High — detectors disagree, many flag |
| 61–74 | Lower risk | Some AI signals remain | Moderate — some tools flag, others pass |
| 75–84 | Passes most detectors | Mostly human signal pattern | Low — passes major tools under normal use |
| 85–100 | Strongly human | Clear human authorship signals | Very low |
What Actually Moves the Score
This is the practical part. If you're looking at a score of 54 and wondering how to get to 75, here's what matters.
What pulls the score DOWN
AI-associated phrases. TextSight's AI Vocabulary Highlighter identifies the specific phrases in your text that are over-represented in AI output. "It's worth noting that," "delve into," "crucial role," "as we move forward" — these each knock 5–10 points off your score when they appear in density. The hit is cumulative.
Low sentence length variance. AI tends to write sentences of similar length within paragraphs. Humans vary wildly — short punchy sentences followed by longer, more complex ones that build out an idea across multiple clauses and qualifications. A paragraph where every sentence is 18–24 words reads as AI, even if none of the individual sentences seem unusual.
Predictable paragraph structure. Topic sentence → evidence → restatement. This structure is baked into most AI outputs because it was trained on academic writing that follows this pattern explicitly. Human writers deviate from it constantly — we start with the evidence, or start with a question, or start with a counterpoint.
Generic examples. "For example, consider a company that wants to improve efficiency." That's an AI example. No company, no name, no specificity. Human writers use real examples from their experience or the news.
Missing first-person signals. "This suggests that..." reads AI. "What I've found is..." reads human. Personal voice markers — including stating opinions, acknowledging uncertainty, referencing personal experience — push the score up.
What pushes the score UP
Sentence length variation. The single biggest lever. If your current text has 15 sentences in a row averaging 20 words each, break two of them into fragments. Extend one into a longer, more qualified version. The variance alone can move a score 8–12 points.
Specific examples. Replace "a major retailer" with "Target's Q3 2025 campaign." Replace "many studies" with "a 2025 Oxford study of 847 workers." Specificity is one of the strongest human signals.
Opinions and hedged assertions. Not just "this approach has benefits and drawbacks" — that's balanced-nothing. "This approach works better for smaller teams but breaks down above 50 people, in my experience." The opinion matters. The specificity matters.
Contractions and informal markers. "It is" becoming "it's." "You should not" becoming "you shouldn't." These push the score up reliably. Not because AI never uses contractions — it does — but because the density and placement of informal markers in natural human writing is distinctive.
Paragraph breaks and structural variation. Starting a paragraph with a question. Starting one with a number. Starting one with a fragment. These structural signals carry real weight in the scoring model.
The Difference Between a Score and a Label
Here's why the scoring approach matters beyond just being "nicer."
A binary AI/not-AI verdict doesn't give you a path forward. If you're flagged, you're either fighting the verdict (which is stressful and adversarial) or trying to understand why without any specific information.
A score tells you: here's where you are (58), here's what the issues are (highlighted phrases, sentence structure patterns), and here's roughly what you need to do to reach a safer zone. It's diagnostic rather than accusatory.
This matters especially for the false positive case — where a human writer scores 62 because they happen to use formal academic prose. A binary "AI detected" verdict from a tool that's wrong here creates a crisis. A score of 62 with highlighted phrases creates an explanation: these are the specific patterns that flagged you, here's why, here's what you could change if you want to lower the ambiguity.
The score acknowledges that there's a spectrum. Some text is clearly AI. Some is clearly human. A lot of real-world text in 2026 sits somewhere in between — written by humans using AI tools, edited AI output, or human writing that happens to share stylistic features with AI. Binary tools can't handle that reality honestly. A score can.
Common Misconceptions
"A score above 75 means I'm safe." Close, but not quite. It means you pass most major detectors under normal circumstances. Originality.ai, which is more aggressive, might still flag at 76–78. Turnitin under their highest sensitivity setting might flag at 78–80. "Safe" is context-dependent.
"I need to get to 100." You don't. The difference between 85 and 100 is stylistic, not risk-related. Chasing 100 often leads to overwriting — adding quirks that read as performatively casual rather than naturally human.
"If my score is low, it means the tool thinks I cheated." No. The score reflects linguistic patterns. It doesn't know why those patterns are there. A low score on content you wrote yourself means your writing style overlaps with AI patterns — it doesn't mean you used AI.
"Higher is always better." Generally, yes. But a score of 88 on a formal research paper isn't necessarily good if it means the paper now sounds like a blog post. The score should be in the target range for your context and genre.
How to Use the Score in Practice
If you're a student: run your draft, check the score, use the AI Vocabulary Highlighter to fix the flagged phrases, and re-run. Most students can move from a 45 to a 72+ with 20–30 minutes of targeted editing. That's the difference between likely-flagged and low-risk.
If you're a content writer: the score is a sanity check, not a compliance test. You're looking for anything in the 50s or below that might read as obviously AI-generated to an editor or reader.
If you're an educator: a low score is a starting point for a conversation, not a verdict. Combine it with your own knowledge of the student's typical work. Ask them to explain specific paragraphs. The score is evidence, not proof.
The Humanization Score doesn't make decisions for you. It gives you better information so you can make decisions for yourself. That's what a useful tool does.
Check your Humanization Score free → textsight.ai
Related reading: