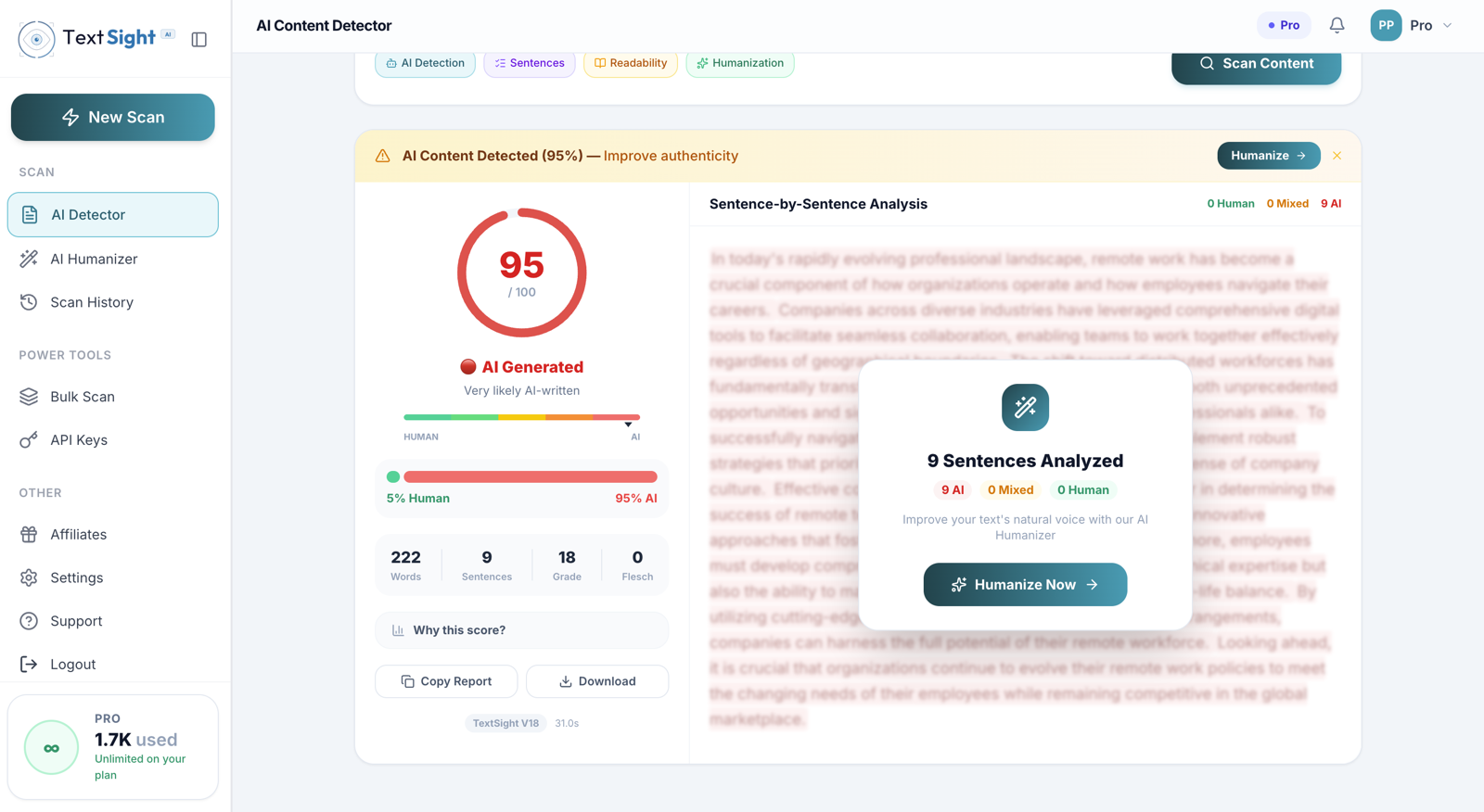
How accurate is detection on GPT-4 output specifically?
On long-form English text of 100 words or more, our internal benchmark puts GPT-4 detection in the 88 to 92 percent accuracy range, and slightly higher on GPT-3.5 because its phrasing is more uniform. Short snippets under 50 words are not reliable for any detector, and the result panel marks those scans as low confidence so you do not over-trust the number.
What about Custom GPTs and GPT Store apps?
Custom GPTs are still GPT-4 or GPT-4o underneath, so the base fingerprints survive. Where they get harder to flag is when a custom system prompt enforces a very specific voice (highly casual, very technical, or styled to mimic a known writer). The Authenticity Score on those scans tends to read mixed rather than clearly AI, and the sentence highlights show you which lines still carry the underlying GPT rhythm.
Can it tell GPT-4o apart from a hypothetical GPT-5?
The detector returns a probability that the text came from the GPT family, not the specific version. Internally we track per-model confidence buckets, but we do not surface "GPT-4o vs GPT-5" as a public label because the difference between two adjacent OpenAI models is rarely reliable at the sentence level. If OpenAI ships a model that breaks the existing pattern signals, we retrain and ship updated weights within days.
Will it flag a fine-tuned GPT model the same way?
Lightly fine-tuned models still produce text with the underlying GPT statistical signature, so detection holds up. Heavy domain fine-tunes (legal, medical, code-heavy) shift the lexical distribution enough that confidence drops, and we surface that as a low-confidence flag rather than a hard verdict. The sentence highlights are still useful because they show which lines retain the base-model rhythm.
What if the ChatGPT output was paraphrased through Claude?
Claude paraphrasing is a known detector workaround, and it does push the ChatGPT-specific score down. The general AI Detector picks the result up under the Claude signature instead, so the overall AI probability stays high. If your goal is "is this AI" then the general detector covers you. If your goal is "is this specifically ChatGPT" then a Claude paraphrase will read as Claude content with GPT-origin clues only in a few residual sentences.
How is this different from the general AI detector?
The general detector returns one overall AI probability calibrated across GPT, Claude, Gemini, Llama, and Mistral. This ChatGPT-specific page focuses the same engine on OpenAI signatures and returns a GPT-probability score, which is what you want when you need to specifically attribute content to ChatGPT (the most common source in education and content workflows). You can use both in the same scan to compare attributions.
Does it false-positive on formal or academic writing?
Formal English shares some surface features with ChatGPT output, especially uniform sentence length and frequent transitions. We hold the false-positive rate on hand-written graduate-level essays low. When the detector is unsure it tags the result as "Mixed" rather than firing a confident AI verdict, and the sentence highlights show you which specific lines are driving the score so you can defend the work line by line.
Is OpenAI's own AI Classifier still around?
No. OpenAI retired its own AI Classifier in July 2023 due to "low rate of accuracy," and they have not shipped a replacement. That is part of why third-party detection still matters: the company that builds ChatGPT does not currently offer a public way to tell whether a piece of text was produced by ChatGPT. TextSight has been training against GPT output continuously since then and ships updated weights with every new OpenAI model release.