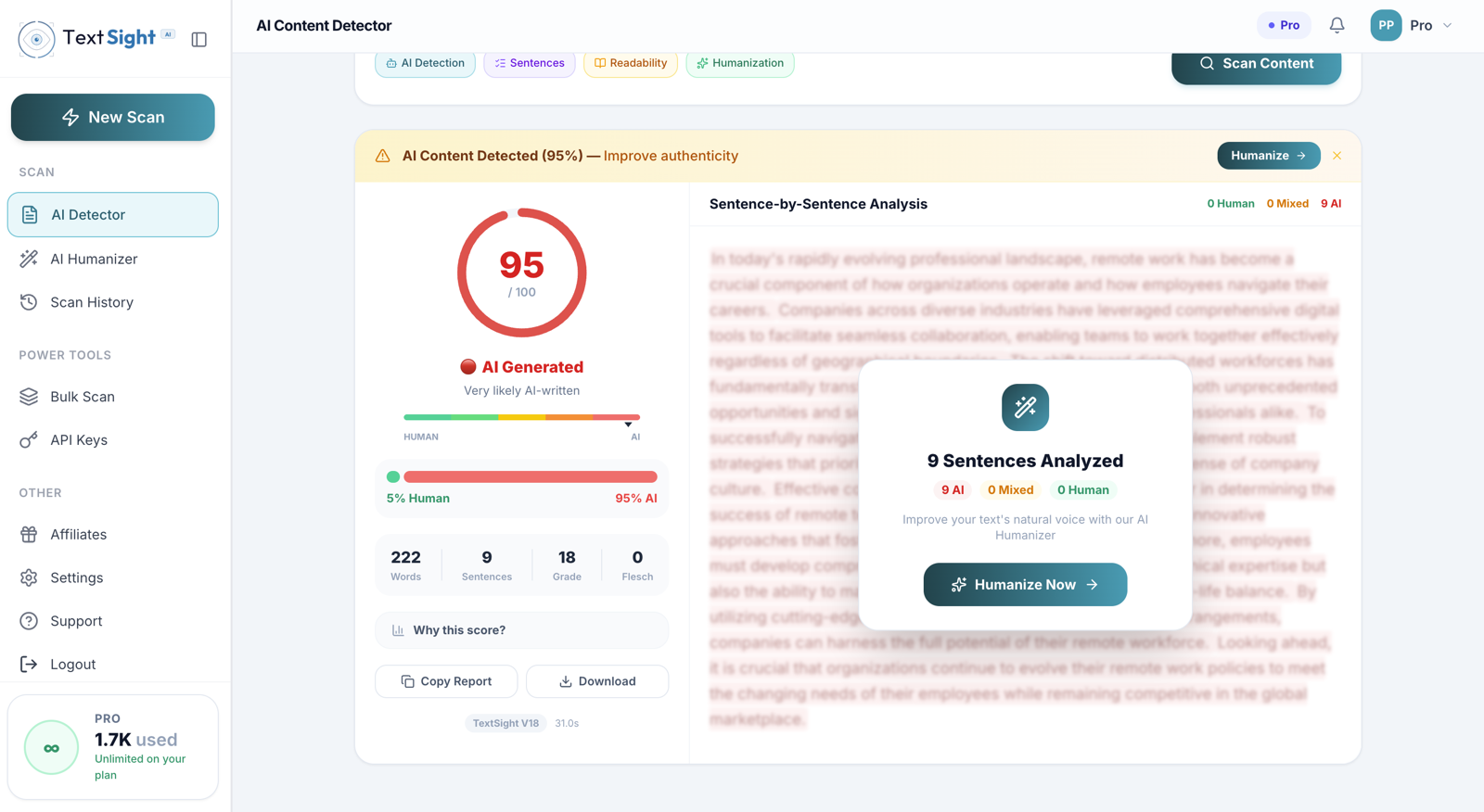
How accurate is the detector, really?
On long-form English content over 300 words against current commercial models (GPT-4, GPT-4o, Claude 3.5/3.7, Gemini, Llama 3, Mistral), our internal benchmark sits at roughly 88 to 92 percent accuracy. On short-form text under 100 words it drops to roughly 70 to 78 percent because there is simply less signal to analyse. We report the band-level verdict so you can interpret confidence directly. Anyone advertising 99 percent accuracy across all content lengths is overclaiming, and we publish the test methodology so you can verify the numbers.
What about false positives on legitimate human writing?
Our internal false-positive rate on human-written text is approximately 2 to 4 percent across general writing samples. That is not zero, which is why TextSight ships sentence-level evidence rather than a single overall verdict. When a borderline score comes back, you can see which specific sentences triggered the signal and decide whether they actually look AI-generated or whether the writer simply has a formal style. The methodology page documents how we measure the rate and on which test corpora.
Does it handle ESL writing fairly?
Better than detectors trained only on native-English corpora, but ESL writing still carries higher false-positive risk because non-native English often shares some surface features with AI text (simpler sentence structures, more consistent vocabulary, fewer idioms). The training set includes a substantial ESL sample, which keeps the rate lower than competitors, but we still recommend ESL writers rely on the sentence-level highlights and Authenticity Score rather than the overall band when stakes are high.
How does it perform on technical and STEM writing?
Technical writing is harder for every detector because dense vocabulary, formulaic structures, and conventionalised phrasing look statistically similar to AI output. TextSight is calibrated against a technical-writing subset (research papers, documentation, white papers) so the false-positive penalty is reduced, but STEM authors should treat borderline scores as a prompt to inspect the highlighted sentences rather than as final judgements. The Authenticity Score is often more useful than the AI probability for technical content.
How often is the model updated as new AI versions ship?
The detector is retrained on a rolling basis as major model releases land. When OpenAI, Anthropic, Google, Meta, or Mistral ship a new flagship version, we capture sample outputs across a range of prompts and writing styles, evaluate detection drift, and roll an updated detector typically within 4 to 8 weeks of release. The methodology page lists the currently-supported model versions and the date of the most recent training refresh.
Does it work on non-English text?
The detector is English-first. It runs on other Latin-script languages (Spanish, French, German, Portuguese, Italian) but accuracy drops because the training corpus is heavily English. For Cyrillic, Arabic, CJK, or Devanagari scripts we recommend a dedicated multilingual detector. If you need detection in a specific non-English language, contact support and we will share the calibration data we have for that language so you can decide whether it meets your bar.
Is there an API for product builders and agencies?
Yes. REST API access is included on the Business plan ($39.99/mo) with 10,000 calls per month, full sentence-level response payloads, SSE streaming for the AI rewriter endpoint, and documented rate limits. EdTech platforms, LMS vendors, agency CMS integrations, and content-quality tools all use the same endpoints the dashboard uses. The full reference is at api-docs, including authentication, request/response schemas, and example payloads.
Which AI models does it detect best?
Detection accuracy is strongest on the major commercial models that dominate the training set: GPT-4, GPT-4o, Claude 3.5, Claude 3.7, Gemini 1.5/2.0, Llama 3, and Mistral Large. Accuracy is solid on smaller variants (Claude Haiku, GPT-4o-mini, Gemini Flash) and degrades gradually on heavily fine-tuned open-source models and on outputs that have been passed through an aggressive third-party AI rewriter. The result panel labels the highest-likelihood model family when the signature is clear, so you know which model the text most resembles.