How exactly is the Authenticity Score calculated?
The score blends five weighted language signals into one 0-100 number: burstiness (variation in sentence length and structure), perplexity (how predictable each next word is for a strong language model), lexical diversity (range and rarity of vocabulary), structural markers (repeated paragraph shapes, predictable transitions, listicle and triplet patterns), and model-specific fingerprints (lexical signatures characteristic of GPT-4, Claude, Gemini, or Llama 3). Each signal contributes a weighted component, the weights are tuned against a benchmark of human-vs-AI authored content, and the result is the 0-100 score you see. The full methodology and benchmark setup live at /accuracy-methodology.
Can the Authenticity Score be wrong?
Yes. The score is a calibrated probability, not absolute truth. Heavily edited AI text can score high. Deliberately stilted human writing (especially in formal academic registers, ESL contexts, or technical documentation) can score low. We surface a low-confidence flag on very short or unusual text so you know when to weight the number less. Use the score as a benchmark and a target, never as the sole basis for a high-stakes decision such as a grade, an invoice dispute, or a publication kill.
Why is my Authenticity Score 35 when I wrote every word myself?
Human writing scores low when it accidentally resembles AI output. The usual culprits: a very even sentence rhythm, heavy reliance on Latin-derived verbs and academic transitions ("moreover," "furthermore," "in conclusion"), parallel triplet structures, hedge phrases ("it is important to note that"), and uniform paragraph shapes. Open the sentence-level highlights, look at which lines triggered, and rewrite those specifically. Vary length, drop one or two transitions, and let one sentence run longer than feels comfortable. The score usually moves into the Mostly Human band after a single pass.
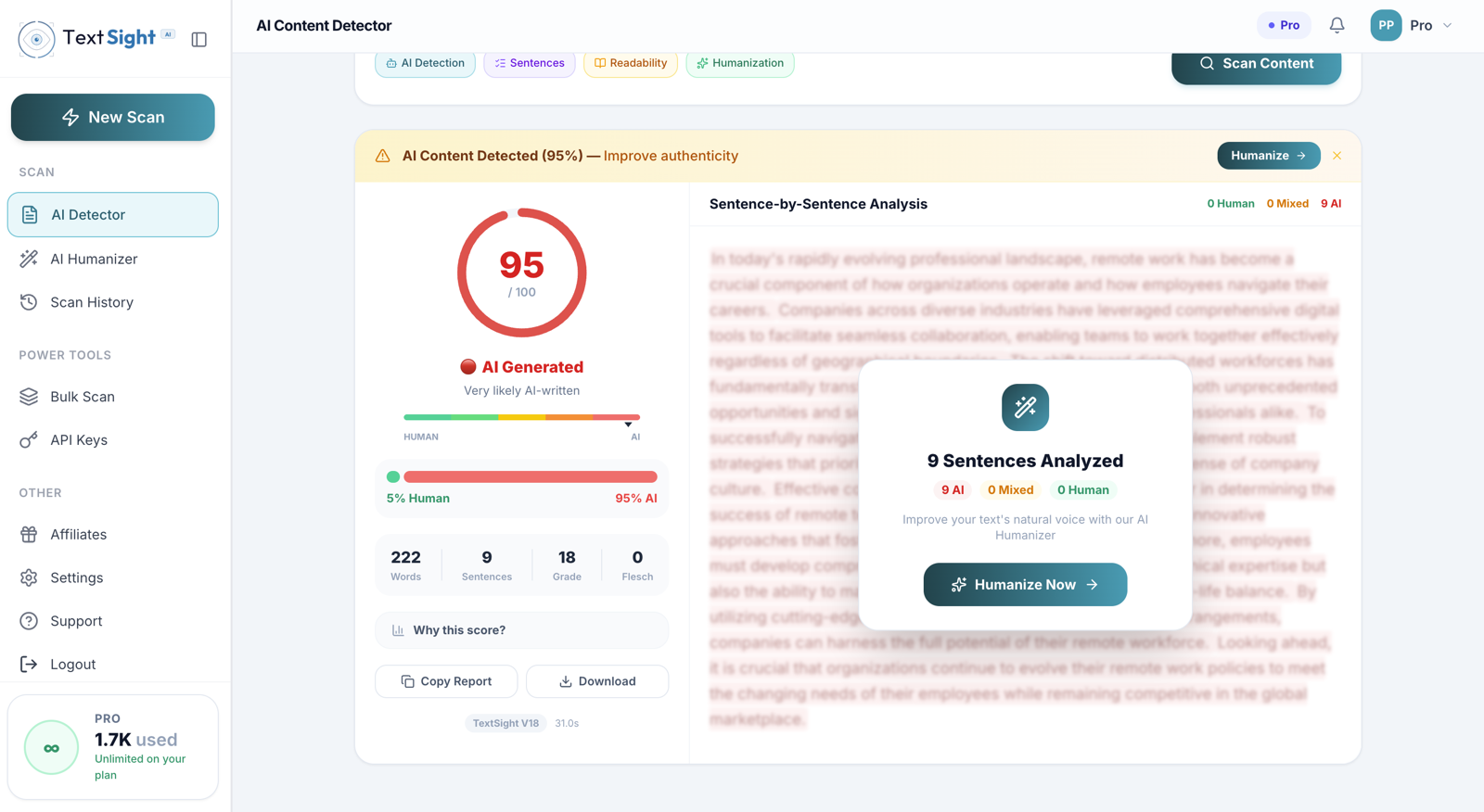
How does the score handle mixed AI-and-human text?
The 0-100 number is computed across the whole passage, so a half-AI half-human draft typically lands somewhere in the Mixed band (41 to 60). The sentence-level highlights are where mixed text becomes useful: each sentence is colour-coded separately, so you can see which paragraphs you wrote and which came from a model. Rewrite the flagged sentences, rescan, and watch the overall score climb. This is the most common workflow for editors handling AI-assisted drafts from contributors.
How does the Authenticity Score compare to GPTZero's score?
GPTZero reports an "AI probability" and a separate burstiness and perplexity figure. The Authenticity Score is the inverse of an AI probability (higher means more human), blended with additional signals such as vocabulary fingerprints and structural markers. Both tools draw on overlapping research, so scores often agree directionally: text TextSight labels Original usually clears GPTZero, and text TextSight labels AI Generated usually fails it. They are not interchangeable, though. Each detector is calibrated against a different benchmark, so do not assume one number maps onto the other. If you need to pass GPTZero specifically, verify there.
Is the score equally accurate across different content types?
No, and we publish the caveats. The score is most accurate on long-form prose (essays, articles, blog posts) of 300 words or more. Accuracy drops on very short text (one or two sentences), code, lyrics, formulaic copy (product descriptions, legal boilerplate), and ESL writing that follows tight stylistic conventions. Technical documentation often scores lower than its quality deserves because dense procedural prose naturally resembles AI rhythm. Treat scores on those categories as directional. Full type-by-type accuracy breakdown is in the methodology page.
Can I export an Authenticity Score report?
Yes. Every scan can be exported as a PDF that includes the overall 0-100 score, the band label, the sentence-level breakdown with colour coding, the timestamp, and the model fingerprints detected. Pro and Business plans get the export unbranded (Business adds white-label support for client deliverables). Free and Starter exports carry a small TextSight footer. Reports are also available via the REST API on the Business plan for teams piping the score into their own dashboards or grading workflows.
What counts as "passing" an Authenticity Score check?
There is no universal pass mark. The right target depends on the stakes. For personal writing or internal docs, any score in the Mostly Human band (61 to 80) is fine. For most blog posts, marketing copy, and Substack pieces, target 70 or higher. For academic submissions, aim for 80 or higher and reread the highlighted sentences before submitting. For compliance, legal, journalism, or anywhere the writing must read as clearly human-authored, target the Original band (81 to 100). And remember: a high TextSight score correlates with passing other detectors but does not guarantee it. If a specific third-party tool is the gate, verify on that tool too.